
Today, Artificial intelligence is often used as a synonym for Machine Learning with Neuronal Networks. Often less resource and pain-free approaches like Random Forest or Support Vector machines are not even mentioned as an alternative to neuronal networks. In this article, we compare Random Forest, Support Vector Machines and Neural Networks by discussing their way of operation on a high level.

Use case Classification
In Machine Learning, Classification is one of the domains of Machine Learning that help to assign a class label to an input.
Such Machine Learning classification can be executed through the means of algorithms such as Random Forest, Support Vector Machines, Random Forest, and not in this article discussed methods.
Just imagine the following: When given an image of a cat, classification algorithms make it possible for the computer model to accurately identify with a certain level of confidence, that the image is a cat.
The input data for classification with machine learning can range from the text, images, documents to time-series data.
This article will help the reader to explain and understand the differences between traditional Machine Learning algorithms vs Neural Neural from many different standpoints.
Branching out of Machine Learning and into the depths of Deep Learning, the advancements of Neural Network makes trivial problems such as classifications so much easier and faster to compute. In September 2002, a newly developed Neural Network architecture called AlexNet managed to classify 1.2 million high-resolution images with 1000 different classes, by training a deep convolutional neural network.

Advancements as such make it so much easier to perform classification and many other problems that we face or are facing. Recently, there is an article whereby Sentiment Analysis algorithm is used on popular social media sites such as Facebook, Instagram and Twitter to analyse the comments, hashtags, posts, tweets and so on to identify the overall manifestations or sentiments of the users on how they feel about COVID 19 in general. This will allow researches to understand the overall feeling of the population in that particular state or country.
What if there are only a limited number of user or public data available to perform the classification?
This is where simple Machine Learning algorithm such as Support Vector Machines (SVM) and Random Forest comes in.
Support Vector Machines in Classification
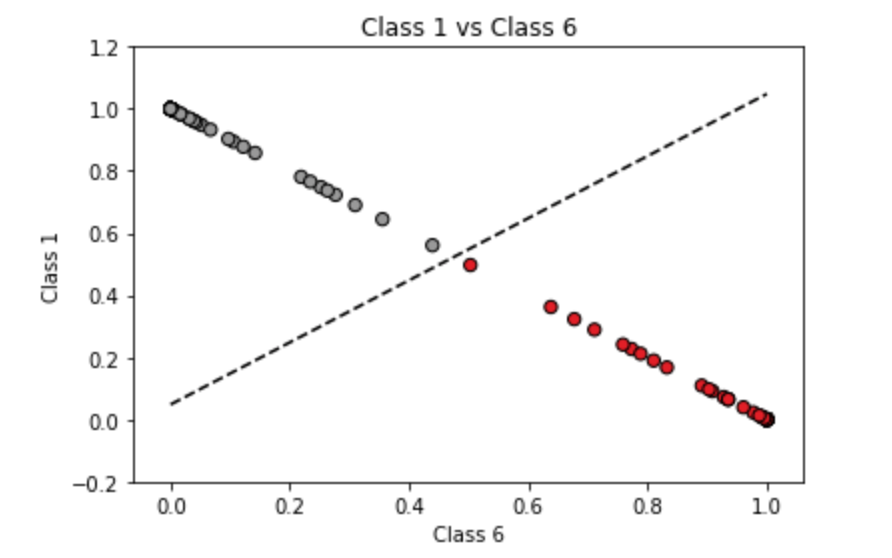
SVM is a supervised Machine Learning algorithm that is used in many classifications and regression problems. It still presents as one of the most used robust prediction methods that can be applied to many use cases involving classifications.
It works by finding an optimal separation line called a hyperplane to accurately separate 2 or more different classes. The goal is to find the optimal hyperplane separation through training the linearly separable data with the SVM algorithm.
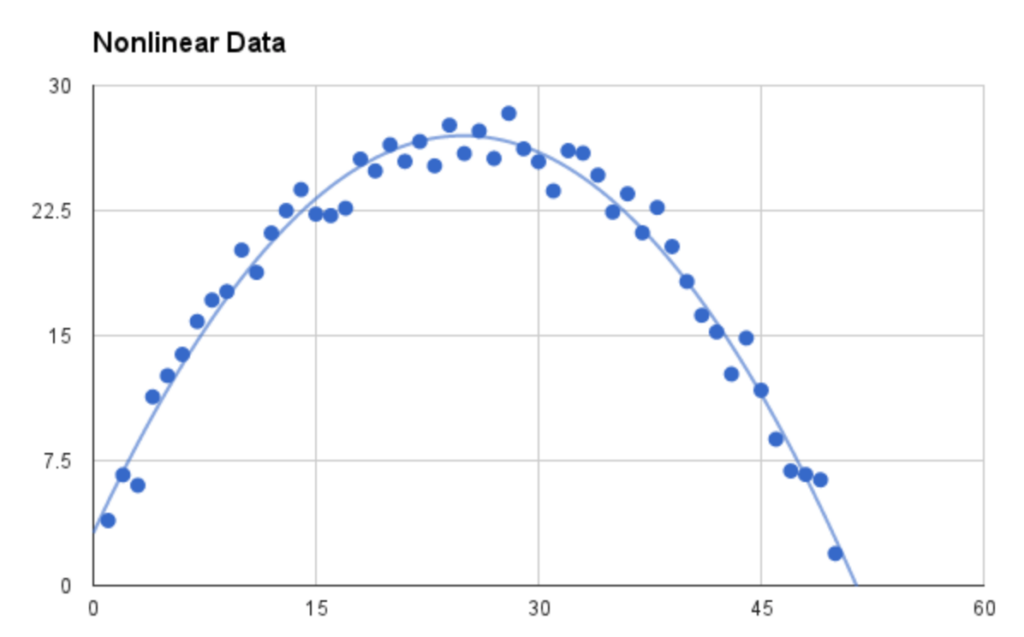
In most cases, the data is linearly separable, whereby a straight line function can be implemented to group 2 different classes. Whereas for non-linear data, the general idea on how to approach this is to map the original feature space to some higher-dimensional space using kernel tricks.
Random Forest in Classification
To understand Random Forest, we have to first understand decision trees. Decision trees in simplest term are basically a decision tool that uses root and branch-like model to identify possible consequences by using control statements. Tree-based computer model or algorithms are considered to be one of the most used supervised learning methods. A simple model as such can also be interpreted as predictive models with high accuracy, stability and ease of interpretation.

Random forest is basically the combination of multiple individual decision trees to act as an ensemble. Ensemble learning can be defined as a paradigm whereby multiple learners are trained to solve the same problem. Ensemble learning actually has been used in several applications such as optical character recognition, medical purpose, etc. In fact, ensemble learning can be used wherever machine learning techniques can be used.
When it comes to classification using Random Forests, the idea is that the combination of outputs of mutually exclusive nodes will outperform any individual models which are then said the predicted output. Combining multiple trees (learner) may be a better choice if the learners are performing well.
Neural Network in Classification
When it comes to classification using Neural Networks, especially, Convolutional Neural Network (CNN), has a different way of operating which in particular could handle both linearly and non-linearly separable data.
For classification purpose, a neural network does not have to be complicated. Neural network for classification is made up of a single hidden layer and a non-linear activation function.
Activation functions are mathematical equations or models that determine the output of a neural network. The function is attached to each neuron in the deep network chain and determines whether it should be activated or not, based on the inputs that are passing through. Activation functions also help normalize the output of each neuron to a range between -1, 0 and 1.
Below are two non-linear activation functions that is commonly applied in Neural Networks :
- Logistic Sigmoid Function – Output probabilities in the range of 0 to 1. Produces a smooth gradient but computationally expensive.
- Hyperbolic Tangent – Outputs will be a vector from -1 to 1. Has stronger gradients compared to sigmoid.
All the functions above takes the linear combination of input vector (x) and feature weight (w) and return an output that is within the range of the activation function applied.
Which Algorithm to choose from?

When it comes down to what specific methods to be used for a classification problem, the data provided is critical. Understanding data plays a role in the process of choosing the right algorithm for the right problem. Specific algorithms can work with fewer sample sets, while others require tons and tons of samples. Some algorithms work with categorical data while others like to work with numerical input.
“What AI and machine learning allows you to do is find the needle in the haystack“
~Bob Work
When determining what algorithm to use, complexity, and time plays a huge role. In a business organisation, most often timely and accurate results are more important than the method used in creating those results.
Hence, it is always a good idea to go with easy implementations to produce results. It is always better to understand the simple questions below before deciding:
- How accurate should the model be?
- How complex is it?
- Can it be interpreted easily?
- Model is able to scale properly?
- Does the model meet the business goal?
- so on…
Number of Total Parameters
- Both Support Vector Machines and Neural Network are parametric. SVM has 2 parameters namely C and Gamma whereas for NN, it mostly has to depend on the number of layers in the network, learning rate and epoch.
- There are not many parameters to be controlled in Random Forest, but the depth of the forest and the number of trees in each level can be tuned to reduce or increase the complexity of training the whole model.
Non-Linear Function Approximation
- Both SVM and Neural Network can map the input data to a higher dimensional space to assign a decision boundary. For SVM, it is done by using kernel tricks whereas for Neural Network via non-linear activation functions. Both classes of algorithms can approximate non-linear decision functions, with different approaches.
- A decision tree is able to handle non-linear data similar to how Neural Network works.
Number of Input Data
Neural Network requires a large number of input data if compared to SVM. The more data that is fed into the network, it will better generalise better and accurately make predictions with fewer errors.
On the other hand, SVM and Random Forest require much fewer input data. Hence, depending on the application and number of data, sometimes SVM or Random Forests can be implemented for a more trivial, less intensive applications.
Optimization Algorithm
- SMV uses Quadratic Programming to perform the computation of the input data. It consists of a function being optimised according to linear constraints on its variables using minimal sequential optimisation, which allows the identification of a feasible solution through iterative computation.
- Neural Network is based on the gradient descent algorithm in most cases.
- There is not much optimisation that could be done for Random Forest since the output mostly depends on, the correlation between any two trees in the forest and the strength of individual trees. However, overfitting tends to happen if the data is not scaled correctly.
Training Input Data Pre-possessing
- Both SVM and Random Forest requires minimal or less significant processing of the input data, which saves lots of time.
- The Neural Network model generally requires a lot more data processing, cleaning, modifying and so on. Typically includes feature scaling, converting categorical to numbers and so on.
More data beats clever algorithms, but better and cleaner data beats more data.
Peter Norvik
Verdict – Which is better?
Most people reading this article are likely familiar with different algorithms used to classify or predict outcomes based on data. However, it is incredibly crucial to understand that a single algorithm cannot be used for all use cases.
Sometimes, Support Vector Machines are more useful compared to Neural Network when you have limited data. And with tabular data, Random Forest is way more accessible to be implemented compared to other algorithms.
When it comes to model performance or accuracy, Neural Networks are generally the go-to algorithm. This is due to its hyperparameter tunings such as epoch, training rate, loss function, etc.
To round the article up, there are always many different algorithms that could be used to demonstrate classification. Which is the best algorithm? We don’t know that actually, as it entirely depends on the types of data and what the end goal is.

Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.