
“Having mere access to data is not going to be the competitive edge anymore. Making sense of this data will be the differentiator that you are looking for,” a quote plucked from ProWebScraper perfectly sums up the need to handle the current explosion of data. The challenge of getting data is no longer the case nowadays as companies are continuously collecting and storing data, most of which end up being unused. The challenges now are to ensure their quality and enable effective data discovery, both of which are made more possible with data curation. This article will introduce the concept of data curation.
What is data curation and why does it matter?

Before knowing what data curation is, let’s first understand what curation is.
“Curation is the work of organizing and managing a collection of things to meet the needs and interests of a specific group of people.”
Definition of “curation” according to Alation.
The term is usually used to refer to collections of artwork, museum artifacts, website content, streamed music, streamed videos and apps.
After collecting the things, the steps of organising and managing them are very crucial in making them easy to find, understand and access.
The same applies to data curation, which is then the work of organising and managing a collection of data sets to meet the needs and interests of specific groups of users.
“Data curation is the process of gathering, maintaining and managing data in repositories in a way that it becomes useful for its end users.”
Definition of “data curation” according to ProWebScraper.
Data Curation can make a positive impact in the following ways:
- Organising data that keeps piling up, so that data scientists can access the data in a usable format regardless of the size of the data set.
- Taking care of the quality of data by identifying useful data and removing useless data. This makes it easier for data scientists to trust and analyse the data.
- Improves machine learning algorithms by feeding well-organised and managed data sets to the machine.
- Making sure that data lakes don’t turn into data swamps.
- Bridging the gap between the data scientists and data engineers, who don’t have a common understanding of the data and the processing required to make it available for analysis.

Since it’s not regularly performed by data scientists or engineers themselves, no one is actively curating data.
That’s why it’s important to have a data curator in charge of data curation.
“Data curators fill this [data understanding] gap and streamline the process of sourcing, organizing, and accelerating data for analysis.”
Dremio’s VP of strategy and CMO Kelly Stirman wrote in his article.
The role of data curators
Studies in the past have attempted to establish the role of data curators but have shown that the data curators’ role wasn’t well-defined.
One such study found that there were many terms used to describe the emerging discipline of data curation including digital curation, digital archiving and digital preservation.
However, the same study also found a mismatch between what people thought of data curation jobs and the actual data curation work.
Most of the interviewees in the study mentioned that they were not managing data directly, but instead, were assigned to educate and consult researchers about good data curation practices.

But it looks like, as time goes by, it’s increasingly becoming clear that the data curator is directly responsible for adding value to and maintaining digital assets over their lifecycles, because they:
- are closer to the business units, so they understand the data and analytics workloads better than data engineers.
- understand the types of data storage systems and data processing tools.
- have updated knowledge about data sets, their provenance and what is needed.
- understand the different types of analyses for specific data sets.
- understand the various business users’ expectations of latency and availability.
- familiar with the processes of planning, creation, collection, processing, analysis, preservation, sharing, and reuse of data.
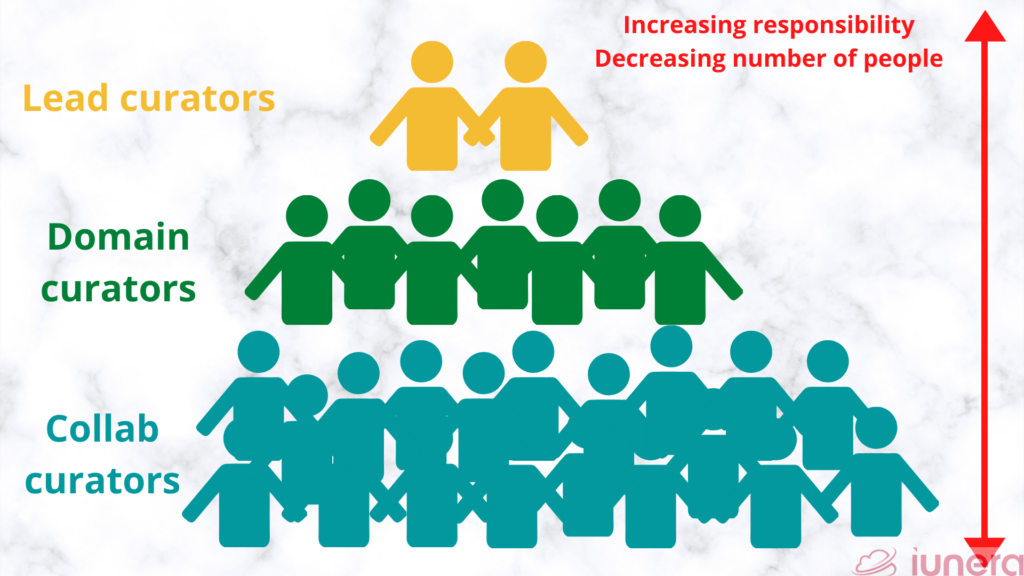
Alation splits the data curator’s role into three levels of responsibilities:
- Collaborative curators: This level indicates that everyone who works with data is involved in crowdsourcing tribal knowledge. Collaborative curators are larger in number but with less responsibility and time commitment.
- Domain curators: Domain curators, who are experts in specific data domains (customer, product, finance, etc.), record and share data domain knowledge. The number of domain curators is smaller than collaborators but have more responsibility and time commitment.
- Lead curators: A lead curator is in charge of moderating data catalogs, particularly metadata quality, which requires lots of responsibility and time commitment.
Regardless of whether a data curator is a collaborative, domain or lead curator, the data curation process should, at least, involve these steps:
- Identifying: Before working on a problem or project, the different data sources need to be identified first.
- Cleaning: The data set might be filled with incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data, which need to be fixed or removed via data cleaning/cleansing.
- Transforming: Data transformation is the process of converting data from one format to another when migrating data from one system to another, especially if the source system and new destination system are in different formats.
An application of data curation
The Geological Survey Alabama (GSA) is an example of how data curation is applied in the real world.
The GSA is in charge of exploring, characterising and reporting data on Alabama’s mineral, energy, water and biological resources for conservation, management and public policy in Alabama.
With this responsibility, the GSA has been asked to make the data more accessible to stakeholders.
Even then, the budgets are small, so more has to be done for less.
That’s why the GSA is applying the “agile curation” to revive their dark data through data curation while taking a page out of the Agile approach.
Data curation can help determine which parts of dark data are useful and which parts are useless for GSA’s efforts.
What can we conclude about data curation?
In today’s world, large amounts of data are collected and stored by organisations. But organisations don’t always know what to do about some of the data, so they leave the data unused.
Having a lot of unused data take up space in the data storage affects the quality and accessibility of data. This problem is one of the things that can be tackled by data curation.
In order to make a data set useful to its users, a data curator needs to have a good knowledge of the data set, as well as the processes, systems and tools required to fulfil the needs of users.
In addition, assigning a data curator or a team of data curators would help streamline the process of identifying, cleaning and transforming data for analysis.
A streamlined data curation process will allow data users to focus more of their time and effort on their own tasks instead of data preparation, and enable the continuity of data management.