
What is the use of Bloom filters, and why are they used?
Eliminating duplicates is an important operation in traditional query processing, and many algorithms have been developed to perform that.
In this article, we will look at one of the most common algorithms called Bloom filter and the algorithm’s working principles.
What is a Bloom Filter?
Supposedly you are creating a new account on this new social media page to connect with your friends. When you enter the username, a message pops up saying, “sorry, the username has been taken”. You added your birth date along with your username, still no luck. Does this sound familiar or frustrating?
This is where the Bloom filter algorithm comes in. Burton Howard Bloom, after whom the algorithm was named, studied computer science at MIT from 1963 to 1965. He invented the data structure that came to be known as the Bloom filter in 1970 while working at Computer Usage Company.
A Bloom filter is a space-efficient probabilistic data structure used to test whether an element is a set member. This means that the algorithm is most commonly used in duplicate event detection. For example, checking the username availability is a set membership problem, where the set is the list of all registered usernames.
In the world of Big Data, data is being generated at a speed that makes it very tough to process the data efficiently. With algorithms such as Bloom filter, it can quickly sort out the duplicate events or data, making it easier to handle the data.
What is Hashing?
To understand Bloom filter, let us take a step back and understand ‘hashing’.
A hash is like a fingerprint for data. A hash function takes your data — which can be any length — as an input and gives you back an identifier of a smaller (usually), fixed (usually) length, which you can use to index or compare or identify the data.
In other words, hashing algorithms are functions that generate a fixed-length result (the hash or hash value) from a given input. The hash value is a summary of the original data. Below is a flowchart of how simple hashing algorithms works.
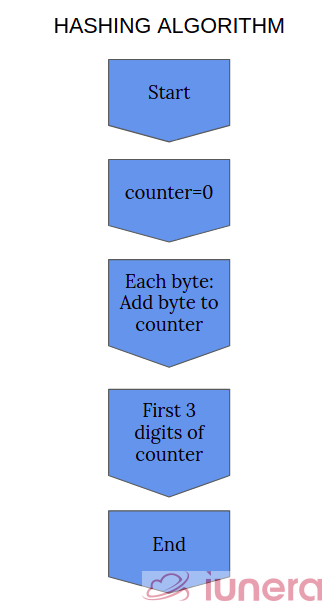
There are a few properties that are desirable in a useful hash function. The most important one is that the same input must always hash to the same output. That’s the defining feature. If the same information give you a different result each time, it wouldn’t be beneficial as an identifier. Ideally, the output values should be distributed uniformly — that is, each possible output should be equally likely. How is this related to the Bloom filter? Let us take a look.
Principles of a Bloom Filter
Bloom Filters are data structures that allow you to:
- Insert an element into a set
- Allow you to query whether an element is in a set
Bloom Filter’s thing is that when the answer to the query is “YES”, it can be wrong. “NO” answers are always correct. The incorrect “YES” answers are probabilistic. Their probabilities can be quantified as a function of the number of elements in the set, the Bloom Filter size, and a parameter k, which is called “the number of hash functions”.
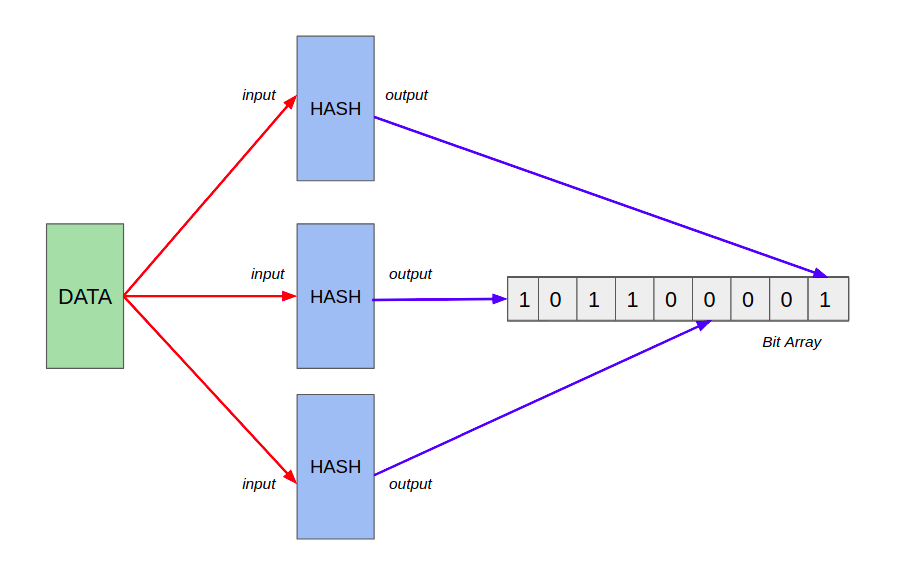
Bloom filters use hash functions to record the membership of added elements, as explained above. Let’s take a look at a simple example of adding an element into an array.
- An empty bloom filter is a bit array of m bits, all of which are initially set to zero.
- To add an element, feed it to the hash functions to get k bit positions, and set the bits at these positions to 1.
- To test if an element is in the set, feed it to the hash functions to get k bit positions.
- If any of the bits at these positions is 0, the element definitely isn’t the set.
- If all are 1, then the element may be in the set.
Let us take a deep look at point 5. If the bit is 1, this tells us that the value is probably in the set. This is because there is a chance that the algorithm inserted another element with the same hash value. This is what is called a hash collision. Hash collisions are common with smaller-sized bit arrays.
How can we reduce the probability of hash collisions from happening?
We should have some estimate for how many values we want to insert. This estimate should then be used to choose an appropriate size for the output bit array. By choosing a large enough size, we can ensure that the expected number of False Positives is quite low.
Properties of a Bloom Filter
Bloom filter is an interesting algorithm that can be applied in many scenarios. Let us take a look at some of the properties of the Bloom filter.
- Bloom filter of a fixed size can represent a set with an arbitrarily large number of elements, unlike a hash table.
- Bloom filters never generate False Negative result. It can only generate False Positives.
- Adding an element never fails. However, the False Positive rate increases steadily as elements are added until all bits in the filter are set to 1, at which point all queries yield a positive result.
- We cannot delete an element in Bloom Filter.
If we want to store a large list of items in a set membership, we can store it in hashmap, tries, simple array or linked list. All these methods require storing the item itself, which is not very memory efficient. Bloom filters do not store the data item at all. As we have seen, they use a bit array which allows hash collision. Without hash collision, it would not be compact.
Advantages of a Bloom Filter
The algorithm is widely adapted to detect duplicate event in many data structures and data types. Let us take a look at some of the advantages that a Bloom filter has.
- The Time Complexity associated with the Bloom filter data structure is O(k) during Insertion and Search Operation, where k is the number of the hash function implemented.
- Space Complexity associated with Bloom Filter Data Structure is O(m), where m is the array size.
- Compared to a hash table where a single hash function is used, Bloom Filter uses multiple hash functions to avoid hash collisions
Drawbacks of a Bloom Filter
There are some notable drawbacks when using the Bloom filter for duplicate event detection.
- There are false positives. This means that the algorithm cannot accurately determine whether the element is in the collection or not.
- The element itself cannot be extracted, only the probability.
- The more hash functions you have, the slower your bloom filter, and the quicker it fills up. If you have too few, however, you may suffer too many false positives.
Other Algorithms
In the Bloom filter case, there are other algorithms out there that can perform almost the same function. For example, an algorithm called Local Sensitive Hashing, or in short, LSH can be used as an effective way of reducing the overall dimensions of your data.
LSH is commonly used to deduplicate large quantities of documents, webpages, and other files.
k-Nearest Neighbors is also another algorithm that can be also be used in dimensional reduction using the Neighborhood Components Analysis¶
Summary
To recap this article, a Bloom filter is a data structure designed to tell you, rapidly and memory-efficiently, whether an element is present in a set or not.
Bloom filters allow an element to be inserted into the set and to check if the element is present in the set or not. To store an element into the set, Bloom filters use hash functions to record added elements’ membership.
Some of the Bloom filter properties include that the filter of a fixed size can represent a set with an arbitrarily large number of elements. Bloom filters never generate False Negative result, but only false positives.
Are you looking for ways to get the best out of your data?
If yes, then let us help you use your data.
Related Posts
Frequently Asked Questions
What is a Bloom Filter?
A Bloom filter is a space-efficient probabilistic data structure used to test whether an element is a set member
Why use Bloom Filter?
The Bloom filter algorithm is most commonly used in duplicate event detection
What is Hashing and why is it used in the Bloom filter?
A hash is like a fingerprint for data. A hash function takes your data as an input and gives you back an identifier. Bloom filters use hash functions to record the membership of added elements.
Advantages of a Bloom Filter
The Time Complexity associated with the Bloom filter data structure is O(k) during Insertion and Search Operation. Compared to a hash table where a single hash function is used, Bloom Filter uses multiple hash functions to avoid hash collisions.
Drawbacks of a Bloom Filter
There are false positives, meaning the algorithm cannot accurately determine if the element exists or not. The more hash functions you have, the slower your bloom filter, and the quicker it fills up.